Scaled RBF Attention: Trading Dot Products for Euclidean Distance
If you crack open the architecture of almost any modern Transformer, you will find Scaled Dot-Product Attention (SDPA) sitting at its core. We rarely second-guess it. It is heavily optimized by hardware accelerators, it scales beautifully, and empirically, it runs the world. But if you look closely at the underlying math, treating a dot product as a proxy for "similarity" carries some subtle structural baggage: it is highly sensitive to vector magnitude.
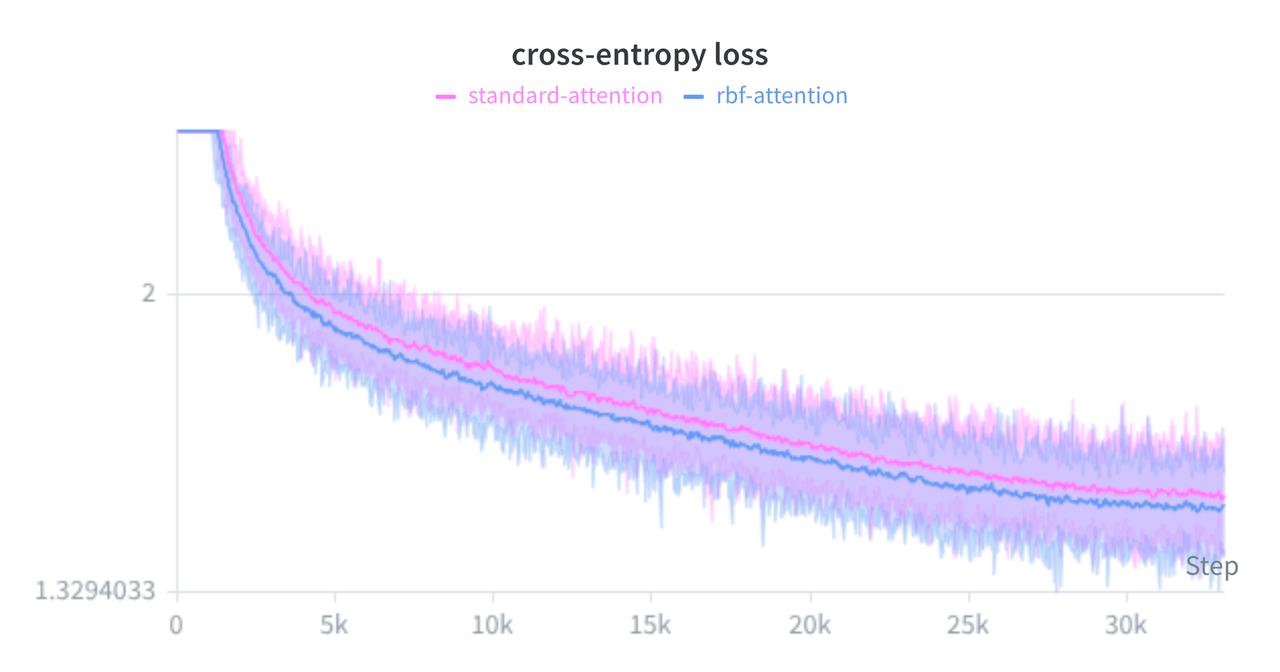
In this post, we'll explore an experimental alternative: Scaled Radial Basis Function (RBF) Attention. By swapping dot products for Euclidean distance, we naturally penalize "loud" keys and aim to stabilize training. I'll walk through the algebraic trick that makes this viable on existing hardware, share a custom Triton kernel for memory efficiency, explain why we need to introduce "Register Tokens" to make it work, and review the empirical results of training a small causal language model from scratch.