Scaled RBF Attention: Trading Dot Products for Euclidean Distance
If you crack open the architecture of almost any modern Transformer, you will find Scaled Dot-Product Attention (SDPA) sitting at its core. We rarely second-guess it. It is heavily optimized by hardware accelerators, it scales beautifully, and empirically, it runs the world. But if you look closely at the underlying math, treating a dot product as a proxy for "similarity" carries some subtle structural baggage: it is highly sensitive to vector magnitude.
In this post, we'll explore an experimental alternative: Scaled Radial Basis Function (RBF) Attention. By swapping dot products for Euclidean distance, we naturally penalize "loud" keys and aim to stabilize training. I'll walk through the algebraic trick that makes this viable on existing hardware, share a custom Triton kernel for memory efficiency, explain why we need to introduce "Register Tokens" to make it work, and review the empirical results of training a small causal language model from scratch.
The "Magnitude Bullying" Problem (And Why It's Actually a Feature)
To understand why an alternative might be useful, we have to look at what the dot product is actually measuring. Recall the geometric definition of a dot product between two vectors:
$$ Q \cdot K = ||Q|| \cdot ||K|| \cdot \cos(\theta) $$
Standard attention wants to find keys that point in the exact same direction as the query (maximizing the cosine similarity). But because the physical lengths of the vectors ($||Q||$ and $||K||$) are multiplied directly into the final score, a key vector that points in a completely mediocre direction but happens to have a massive norm can easily outscore a key that is perfectly aligned but shorter.
In standard attention mechanisms, vectors can sometimes "shout" over much better conceptual matches simply by being physically larger. Initially, I viewed this "magnitude bullying" as a pure structural bug, basically a theoretical impurity that contributes to softmax saturation and suffocates gradient flow during early training.
But what if it's actually a feature?
Recent discoveries, most notably the Attention Sinks phenomenon detailed in the StreamingLLM paper (Xiao et al., 2023), show that Transformers need a place to dump excess "attention mass" when no specific token in the context is highly relevant to a query. Standard attention solves this by learning massive key vectors for seemingly useless tokens (like the <BOS> token or punctuation). A model creates a "sink" simply by scaling up the magnitude of a key; it instantly attracts attention from everywhere.
A more grounded, physical way to measure similarity is to look at the actual distance between the two vectors. Instead of taking a projection, what if we used the negative squared Euclidean distance?
$$ \text{score} = -||Q - K||^2 $$
(Note: Just like standard attention, we scale this distance by a temperature factor like $\gamma = 1/\sqrt{d}$ so the vast distances inherent to high-dimensional spaces don't crush all the probabilities to zero).
This is the core idea behind Scaled RBF Attention. To get a high attention score, $Q$ and $K$ actually have to be close to each other in the high-dimensional space. A vector cannot cheat the softmax by lazily scaling up its magnitude. As an elegant side effect, the maximum pre-softmax score you can possibly achieve is exactly 0 (which happens when $Q = K$). This naturally caps the logits, keeping the softmax outputs bounded right from the start of training.
The Catch: We Just Broke Attention Sinks
By fixing the "magnitude bullying" bug, we accidentally destroyed the model's ability to create attention sinks. Because of our Euclidean math, a key cannot act as a sink by simply being large (an infinitely large key would result in an attention score of $-\infty$, or probability $0$).
To act as a universal sink in Euclidean space, a key must be placed exactly at the geometric origin ($K = \vec{0}$). Because the origin is roughly equidistant from all queries, it is the mathematically perfect "fallback" location. However, if the model pushes a real, semantic token (like <BOS>) to the origin, it destroys that token's semantic meaning. Semantic tokens need to live out in the space to be distinguishable. They cannot safely sit at the origin.
The Fix: Register Tokens
To give our RBF model a place to safely "waste" attention, we can borrow a brilliant architectural hack: Register Tokens (introduced in Vision Transformers Need Registers, Darcet et al., 2023).
By prepending a few learnable, blank dummy vectors to our sequence before it enters the Transformer blocks (and slicing them off before the final output head), we give the model tokens that have zero semantic meaning. The optimizer is now free to take the keys of these Register Tokens and drop them exactly at the origin. Whenever a query looks around the high-dimensional space and thinks, "Nothing here is relevant to me," it naturally falls back to the origin, safely dumping its attention mass into the Register Tokens without corrupting actual text tokens.
The Positional Encoding Clash (Enter SuSiE)
If you drop RBF attention into a modern architecture, you will immediately collide with another dot-product native standard: Rotary Position Embeddings (RoPE).
RoPE explicitly rotates vectors. This is mathematically elegant for standard attention because the dot product of two rotated vectors gracefully translates into a relative phase shift. However, Euclidean distance measures absolute spatial placement. Rotating vectors interacts poorly with Euclidean space.
To make distance-based attention work, I explicitly bypassed RoPE and implemented Subspace Sinusoidal Embeddings (SuSiE). Instead of rotating $Q$ and $K$, SuSiE simply adds cached unrotated sinusoids directly to the vectors. Because it's additive, the Euclidean distance natively expands to include the positional distance $||P_q - P_k||^2$. If two tokens are far apart sequentially, their positional distance acts as a massive mathematical penalty, naturally enforcing a local attention bias.
The $O(N^2)$ Memory Wall
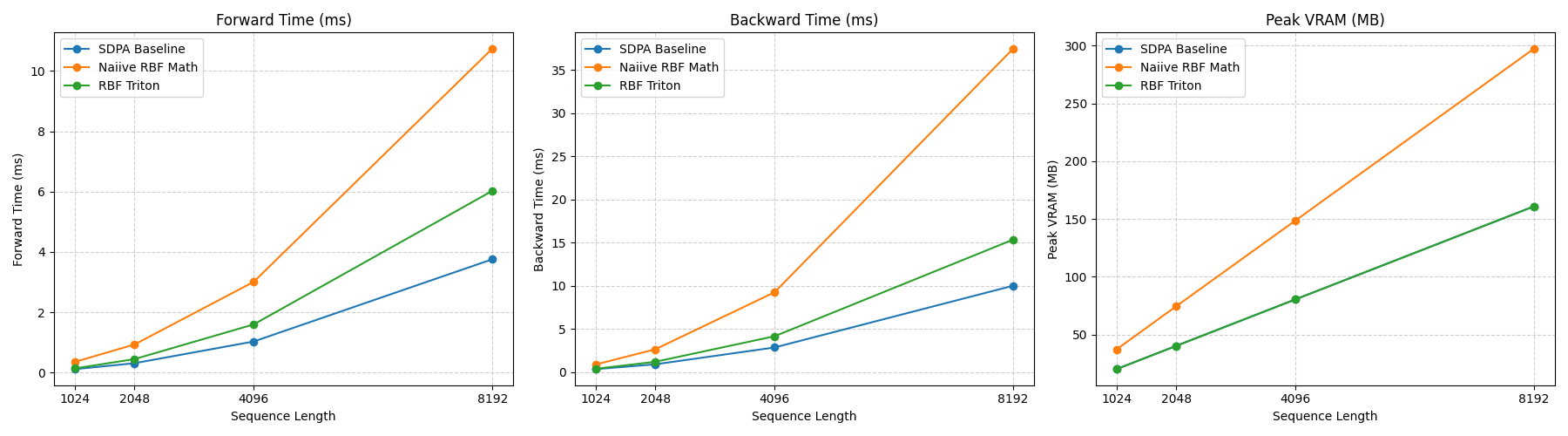
The theory sounds great, so why isn't everyone doing this? The answer, as is often the case in deep learning, boils down to hardware optimization. If you try to implement distance-based attention naively in PyTorch, you will immediately hit a wall of Out-Of-Memory (OOM) errors as your context window grows:
# A quick recipe for an OOM error on your GPU dist = torch.cdist(q, k, compute_mode='donot_use_mm_for_euclid_dist')**2 attn = F.softmax(-gamma * dist, dim=-1) attn_output = torch.matmul(attn, v)
Standard dot-product attention avoids this memory bottleneck thanks to algorithmic breakthroughs like FlashAttention. These fused CUDA kernels are brilliantly engineered to compute the attention weights in ultra-fast SRAM, chunk by chunk, ensuring the massive $N \times N$ attention matrix is never actually materialized in global high-bandwidth memory (HBM).
However, FlashAttention is strictly hardcoded to compute Scaled Dot-Product Attention (SDPA). It doesn't know how to deal with Euclidean distances.
The Algebraic Trick
Before we resign ourselves to writing a custom CUDA kernel from scratch, it turns out there is a rather beautiful algebraic trick to bridge the gap. Let's expand the scaled squared distance formula:
$$ -\gamma ||Q - K||^2 = -\gamma ||Q||^2 - \gamma ||K||^2 + 2\gamma(Q \cdot K) $$
Remember that we are about to feed these scores into a Softmax function operating across the keys (the sequence dimension). From the perspective of the Softmax over a specific row, the query vector is fixed. That means the query norm ($-\gamma ||Q||^2$) is just a constant added to every element in that row.
Softmax has a wonderful property: it is shift-invariant. Adding or subtracting a constant to every term in the input doesn't change the final output distribution at all. Therefore, we can safely drop the query norm from the equation entirely without altering the math.
We are left with a vastly simplified scoring function:
$$ \text{score} = 2\gamma(Q \cdot K) - \gamma ||K||^2 $$
The "Regularized Key Norm" Interpretation
If you look closely at that remaining equation, a fascinating insight drops out.
The first term, $2\gamma(Q \cdot K)$, is precisely the standard scaled dot-product attention we already know and love (just scaled by a factor of 2). The second term, $-\gamma ||K||^2$, acts as a dynamic, built-in penalty on the key's magnitude.
This gives us a brilliant intuition for what RBF attention is actually doing under the hood. RBF Attention is mathematically equivalent to standard dot-product attention equipped with a dynamic L2 regularizer. It actively pushes back against the "magnitude bullying" problem. The model is forced to learn meaningful spatial alignments because lazily scaling up a key vector will now trigger the negative squared penalty, hurting its attention score rather than helping it.
Wait, Do We Even Need Softmax?
Standard attention desperately needs Softmax because a dot product is unbounded. Without a denominator to normalize the scores, a highly positive dot product would explode the network.
But look at our RBF score: $\text{score} = -||Q - K||^2$.
The maximum possible score is exactly $0$ (when the distance is zero). If we simply pass this through an exponential function ($\exp(\text{score})$), the output is mathematically guaranteed to be bounded between $0$ and $1$.
This begs a radical question: Can we drop the Softmax denominator entirely?
In the repository, I included an experimental TritonNonSoftmaxRBFAttention kernel to test this. Dropping Softmax means we lose the shift-invariance property, so we can no longer safely ignore the Query norm ($||Q||^2$). The Triton kernel has to compute and subtract the Query norm on the fly. However, bypassing the Softmax denominator entirely removes the need to track row-maximums or row-sums (as it is done in online-Softmax), stripping the inner loop down to pure Tensor Core matrix multiplications. It might open up new ways to optimize the hardware limits of Transformers.
Implementation
1: The Dimension-Padding Hack
Because the equation relies heavily on the standard dot product, we can actually trick existing, highly-optimized SDPA kernels into computing our RBF distance for us. We do this by appending a single dummy dimension to our queries and keys:
- $Q' = [Q, 1]$
- $K' = [K, -0.5 ||K||^2]$
If you take the dot product of the new vectors $Q'$ and $K'$, the trailing dimensions multiply together (resulting in $-0.5 ||K||^2$), and the main dimensions compute the unscaled dot product. We then let the native SDPA scale argument handle multiplying everything by $2\gamma$, effectively recovering $2\gamma(Q \cdot K) - \gamma ||K||^2$.
You can pass these artificially padded tensors directly into PyTorch's F.scaled_dot_product_attention using scale=2.0 / math.sqrt(d).
The Alignment Fix: GPU accelerators and Tensor Cores are notoriously picky; they strongly prefer matrix dimensions that are multiples of 8. Padding a head dimension from 64 to a clunky 65 would normally force unoptimized memory accesses, silently dragging down throughput. However, we can simply pad the newly added dimension with trailing zeros until it hits the next multiple of 8 (e.g., from 65 up to 72). Because $0 \times 0 = 0$, the extra padding doesn't affect the dot product math at all, but it restores near-native Tensor Core speeds! Suddenly, you have hardware-accelerated, memory-efficient RBF attention without writing a single line of low-level code.
2: The Custom Triton Kernel
While the padded SDPA hack is a fantastic prototyping workaround, it still involves creating and moving slightly larger tensors around in memory. To implement this natively and eliminate the overhead of tensor padding gymnastics entirely, I wrote a custom Triton kernel (included in the repository). Writing it in Triton allows us to mirror the tiling logic of FlashAttention while injecting our distance math directly into the fused loop. Here is the block-by-block breakdown of how it works:
- Block-wise Matrix Multiply: It computes a chunk of the $QK^T$ matrix using the hardware's fast Tensor Cores.
- SRAM Norm Computation: It calculates and subtracts the squared $L_2$ norms of the keys ($||K||^2$) completely within the ultra-fast SRAM.
- Fusing Softmax: It scales the result, applies the online Softmax, multiplies by the Value block ($V$), and streams the final output back to global memory.
This approach achieves the exact same mathematical output as the PyTorch padding hack but keeps the memory footprint perfectly linear ($O(N)$) and natively matches the hardware efficiency we expect from modern LLM architectures. No tensor padding gymnastics required.
3: Wiring in the Register Tokens
The best part about the Register Token fix is that it requires zero changes to the complex Triton kernel. Because "attention is just attention," you simply initialize a few learnable parameters, prepend them to the sequence before it enters the Transformer blocks, and slice them off right before the final Language Modeling head. The RBF math naturally routes the fallback queries to these dummy tokens, and the autoregressive causal mask remains perfectly intact (text tokens can look back at the registers, but registers only look at registers).
Implementation Details: Zero-Init & Spatial Isolation Getting this to work in practice required two subtle geometric adjustments:
- Zero-Initialization: If you randomly initialize register tokens, their initial Euclidean distance to the queries will be massive. This pushes the exponential scores to zero, causing dead gradients. By initializing them to exactly $0$, their initial distance is safely just $||Q||^2$, keeping gradients healthy right out of the gate.
- Decoupled Positions: Because register tokens are spatial sinks, they shouldn't be tied to the sequence's timeline. We must give them their own dedicated, learnable positional embeddings so they aren't dragged away from the origin by standard sequence positional encodings.
Empirical Results: A Reality Check on TinyStories
Theory and optimization are fun, but does this alternative actually learn anything useful?
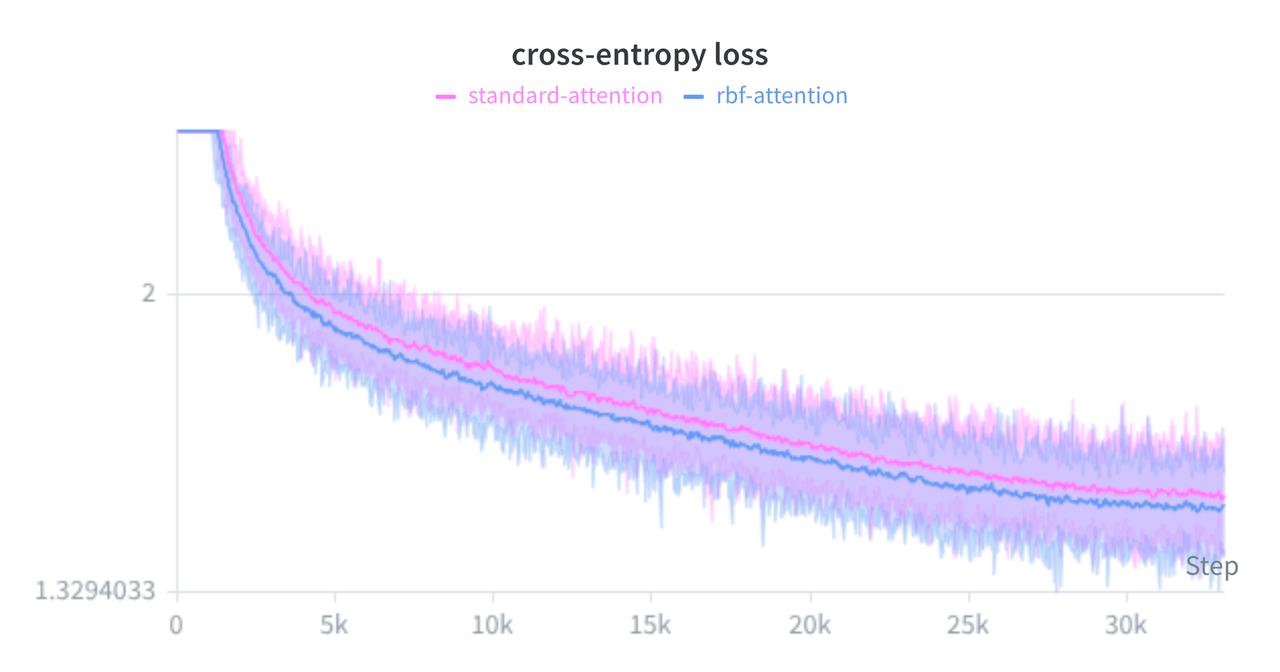
To get an initial sense of its behavior in practice, I trained a small causal language model from scratch on the TinyStories dataset, running a direct head-to-head comparison between a standard SDPA baseline and the new RBF Triton kernel (both with and without Register Tokens to act as attention sinks).
It is important to keep expectations grounded: this is a very small-scale experiment, and we shouldn't read too much into it. That being said, the results were encouraging:
- Training Dynamics: In my limited runs, the RBF model held its own. It converged slightly faster and to a slightly lower validation loss compared to the baseline. While it's tempting to over-claim here and declare it a definitive win, a more honest takeaway is simply that it works. The training curve did appear relatively stable, which loosely supports the intuition that capping logits at $0$ and explicitly penalizing large keys might act as a natural safeguard against early gradient spikes.
- Benchmarking: The custom Triton kernel behaves as expected. Predictably, it is slightly slower than a heavily optimized, vanilla FlashAttention kernel due to the overhead of the extra key-norm calculation. However, it successfully maintains a strictly linear memory profile and scales safely to longer context lengths where the naive PyTorch distance implementation would instantly crash.
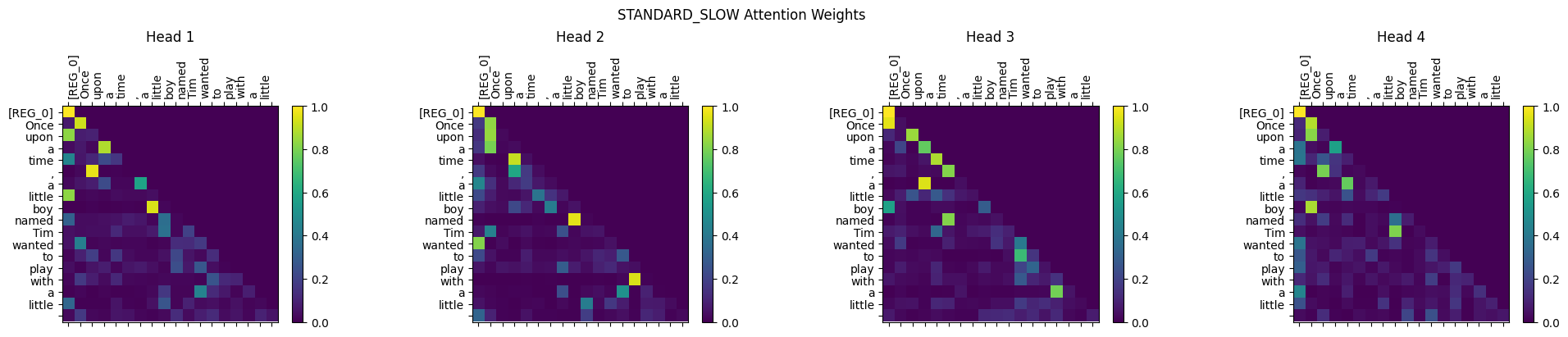
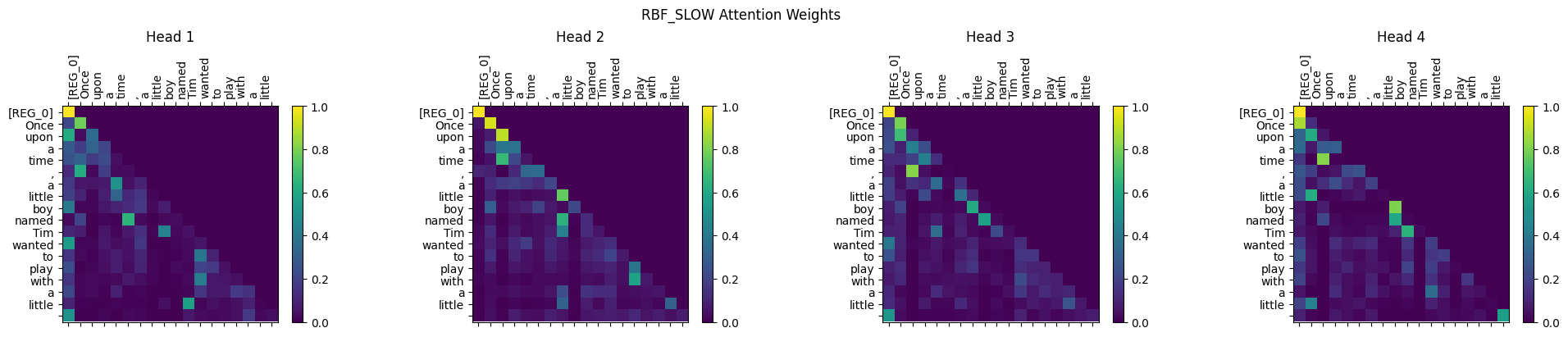
Visualizing the Attention Maps
Notice the [REG_0] token explicitly plotted on the axes absorbing the excess attention mass when no specific sequence token is highly relevant. This serves as the perfect visual proof that our Origin Sink routing is working in practice.
Standard Scaled Dot-Product Attention:
Scaled RBF Attention:
Caveats & Open Questions
Before we start ripping SDPA out of every production system, it's worth stating a few obvious caveats. This project is mostly a fun proof-of-concept meant to challenge our defaults.
- Model Scale: This was tested at the scale of TinyStories, a confined dataset with relatively short context lengths designed to test reasoning in small models. I have no idea how this regularized key norm behaves at the 1B+ or 70B+ parameter scale.
- Inference Constraints: Currently, the custom Triton kernel is optimized for training (the forward and backward passes). I have not yet adapted the logic to support step-by-step generative inference or optimized KV-cache updating.
What's in the Repo
It's always a fun rabbit hole to poke at the foundational math of architectures we take for granted. Tweaking just a few lines of algebra can sometimes yield exactly the geometric properties we want.
If you want to play around with this, I've open-sourced everything here:
-
rbf_attention.py: The core logic containing the padded PyTorch hack, the fused Triton kernels (both Softmax and Non-Softmax variants), and the SuSiE positional encodings. -
test_equivalence.pyandrbf_math_test.py: Unit tests verifying that the Triton kernel matches the naive math down to floating-point precision. -
profile_attention.py: Benchmarking scripts to test memory and throughput on your hardware. -
train_rbf_transformer.py: The full training loop used to generate the TinyStories results, complete with Register Token routing.
Feel free to clone the repo, and run or modify the experiment. If anyone feels adventurous enough to plug this into a larger pre-training run, or knows some Triton black magic to squeeze even more FLOPS out of the kernel, I'd love to hear about it. Issues and PRs are always welcome!
Postscript: Prior Art & The Reality of Hardware Scaling
When a weekend hack actually yields good results, the immediate next thought is usually:
Wait, has someone already done this? And if it works this well, why isn't it powering Llama 3 or GPT-4?
Since this started as a pure experiment, I skipped the literature review at first. But once I had the Triton kernel running and saw that the approach worked pretty well, I finally dug into the prior art. What I found was a great reality check on the gap between algorithmic elegance and systems engineering.
Here is where "Scaled RBF Attention" actually sits in the literature, and why the industry took a different path.
I Wasn't the First (Prior Art)
It turns out the theoretical flaw I mentioned, namely that standard dot-product attention lets vectors "bully" the softmax just by scaling up their magnitude is a known issue.
Back in 2021, researchers at DeepMind published The Lipschitz Constant of Self-Attention (Kim et al.). They proved that dot-product attention is mathematically unstable (not Lipschitz continuous) and proposed exactly this: L2 Distance Attention. They used the same squared $L_2$ distance formulation I arrived at, and also noted that the $||Q||^2$ term safely factors out of the softmax, leaving the exact $2(Q \cdot K) - ||K||^2$ trick.
Of course I didn't expect to have invented this simple math trick, but it's also validating to know my intuition was on the same wavelength as published DeepMind research. But that begs the question: if the theory is solid, why didn't the NLP industry adopt it?
How the Industry Fixed Magnitude Bullying: QK-Norm
As I discussed earlier in the post, what I originally thought was a bug ("magnitude bullying") turned out to be how models create Attention Sinks. While my addition of Register Tokens provides a neat geometric workaround to give RBF its sinks back, the industry solved the stability issue differently: Query-Key Normalization (QK-Norm).
By applying RMSNorm to the $Q$ and $K$ matrices before the dot product (now standard in models like Gemma 2, and ViT-22B), all queries and keys are projected onto a hypersphere.
The math works out beautifully. If $Q$ and $K$ have unit norms, then:
$$||Q - K||^2 = ||Q||^2 + ||K||^2 - 2(Q \cdot K) = 2 - 2(Q \cdot K)$$
On a hypersphere, maximizing the dot-product is mathematically identical to minimizing the Euclidean distance. But wait:
Isn't QK-Norm computationally more expensive than our RBF trick?
On a whiteboard, absolutely. QK-Norm requires reading massive $Q$ and $K$ tensors from memory, squaring them, summing, taking an inverse square root, and writing them back. My efficient RBF formulation avoids all those expensive square roots and divisions, so it feels like it should be strictly faster.
But on modern, hyper-optimized bare-metal GPUs, QK-Norm wins. Here's why:
- Kernel Fusion & Memory Bandwidth: In production, QK-Norm isn't a separate step. It gets fused directly into the kernel that applies Rotary Positional Embeddings (RoPE) or the QKV linear projections. Since the GPU already has the $Q$ and $K$ vectors loaded into its ultra-fast SRAM, applying RMSNorm requires zero extra trips to High Bandwidth Memory (HBM). In terms of wall-clock time, it's essentially "free."
-
Register Pressure in the Inner Loop: FlashAttention is notoriously difficult to optimize because the inner $\mathcal{O}(N^2)$ loop runs right at the physical limits of the GPU's SRAM and register files. My RBF Triton implementation forces the kernel to load an extra vector (
k_sq) into SRAM, hold it in physical hardware registers, and execute an extra pointwise subtraction right before the softmax. Adding even a tiny bit of register pressure to that innermost loop often forces the compiler to reduce the block tile size (e.g., from $128 \times 128$ to $64 \times 64$), or causes "register spilling" to slower memory. -
The FLOPs Distribution: QK-Norm operates on the $N \times d$ tensors before attention, adding $\mathcal{O}(N \cdot d)$ operations. In the RBF Triton kernel, subtracting the
k_sqvector from the attention matrix happens for every single token pair inside the inner loop, which adds $\mathcal{O}(N^2)$ operations. Plus, this pointwise subtraction executes on the slower CUDA Cores (SIMT ALUs), creating pipeline bubbles that can stall the ultra-fast Tensor Cores. As context windows scale to 100K+ tokens, that $\mathcal{O}(N^2)$ subtraction turns into a heavy tax.
Wrapping Up
By moving the mathematical fix out of the attention mechanism via QK-Norm, the industry gets to keep the attention computation as a standard dot-product. This lets AI labs drop in off-the-shelf, hardcore-engineered kernels like FlashAttention, pushing GPUs to their absolute theoretical limits without having to maintain custom Triton kernels for every new hardware architecture.
At the end of the day, building this was a massive learning experience. Deriving the math, finding the algebraic trick to fuse it into PyTorch's SDPA, wiring in Register Tokens, and dropping down into Triton to manage GPU memory hierarchies taught me more about the full ML stack than reading a dozen papers ever could. It was a great lesson in the difference between designing a clever algorithm and engineering a system for the physical realities of modern silicon.